目的
オンラインのLLMのように「Webの最新情報」を反映させる
ChatGPTやGeminiを使うと「Webの最新情報」を元に情報を纏めてくれるのだが、ローカルLLMではそういう機能が提供されていない。
この課題を複数のコンポーネントを組み合わせることで解決させることができる。
ローカルLLMを実用的に使うためのシステム構成
① 各OSSの概要
- open-webui
- ollama
- lemonade
- SearXNG
Open WebUI
- ブラウザからLLMを操作するためのWebインターフェース
- ChatGPTのようなUIをローカル環境で再現可能
- 複数のLLM API(Ollama / OpenAI互換 / 独自API)を統合できる
- プラグインやWeb検索連携(SearXNGなど)に対応
👉 ポイント:「フロントエンド(UI)」担当
Ollama
- ローカルでLLM(GGUFなど)を実行するランタイム
- CLIおよびREST APIでモデルを操作可能
- GPU/CPUで動作し、完全オフライン運用が可能
👉 ポイント:「ローカルLLM実行エンジン」
Lemonade
- 複数のLLMやツールを統合するAPIプラットフォーム
- OpenAI互換APIとして動作させることが可能
- ワークフロー、ツール連携、外部API統合に強い
- ollamaで動かないAMD製GPUでも動く場合が多い
- CLIのパラメータが頻繁に変更されているため注意が必要
👉 ポイント:「LLMの統合・拡張API基盤」
SearXNG
- プライバシー重視のメタ検索エンジン
- Google / Bing など複数の検索エンジンを横断検索
- 自前ホスト可能でAPIとして利用可能
👉 ポイント:「Web検索バックエンド」
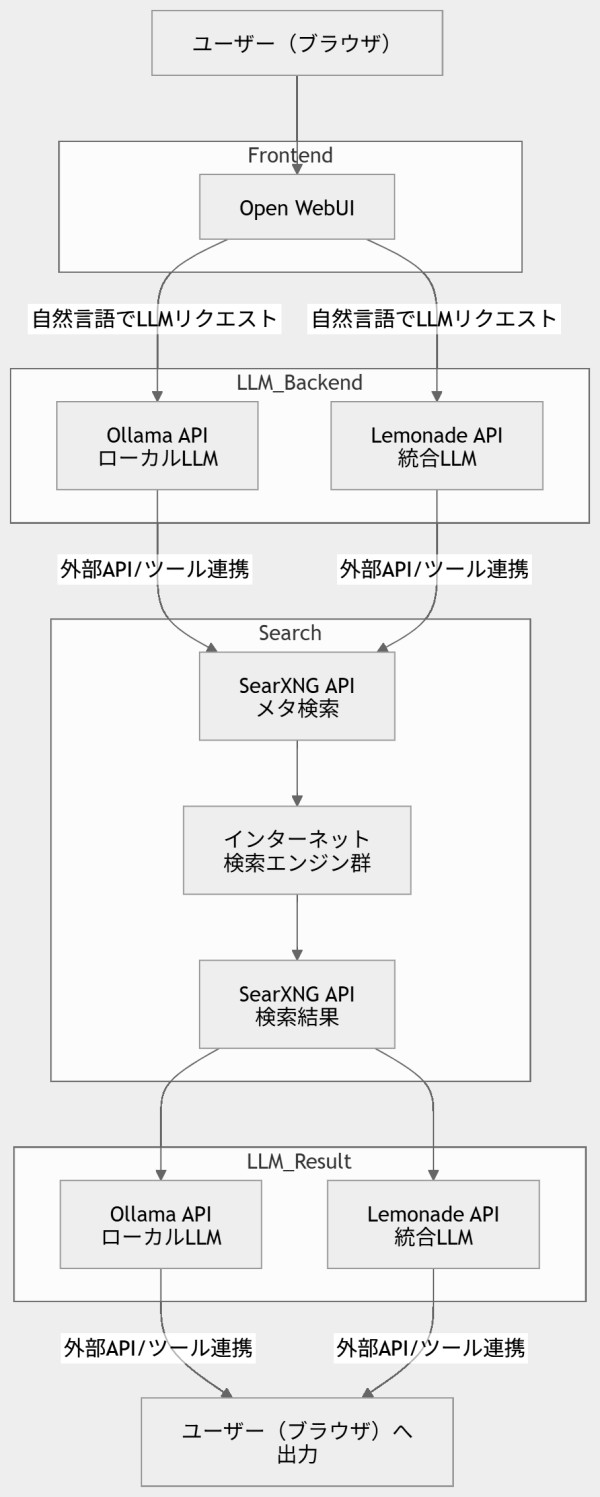
② システム構成図(Mermaid)
以下は、質問の構成(Open WebUI + Ollama + Lemonade + SearXNG)をまとめた構成です。

補足(設計のポイント)
- Open WebUIは単なるUI層なので、すべての処理はバックエンドへ委譲
- Ollamaは完全ローカル処理(オフライン可能)
- Lemonadeは拡張・外部連携用(半クラウド的)
- SearXNGは検索プロキシとしてLLMに情報供給
各システムを構築するにあたり注意点
open-webui
インストール要件
インストールはpipもしくはdockerで簡単に構築できるのだが、APIを仲介するためにポート競合を回避させる工夫が必要。
注意点
open-webui自体はLLMの機能は無い。LLMのAPIを仲介するためのWebUIとして稼働する。Sandboxとしては便利なのだが、検索エンジンとローカルLLMの連携を追求するとopen-webuiを使わずにPython等でプログラムを自作したほうが確実に処理できる。
ollama
インストール要件
インストール専用のshell-scriptが提供されているので最低限の構築はとても簡単。しかし、GPUで推論を動作させるためには事前にGPU用の環境構築が必要。
注意点
- NVIDIA製のGPUを使用する場合
NVIDIAドライバーとCUDAドライバーがインストール済み、かつPyTorchが構築されている前提で、ollamaをインストールしなければならない。 - AMD製のGPUを使用する場合
AMDドライバーとROCmドライバーとVulkanがインストール済みである前提で、ollamaをインストールしなければならない。 - AMD製のiGPUを使用する場合(Radeon,Radeon780M,Radeon890Mなど)
「AMD製のGPUを使用する場合」と同等のドライバーがインストール済みで、かつiGPU用の環境設定が必要なのだが。GPUの環境変数を正しく定義してもollamaのバージョンによって動作したり動作しなくなったり、安定しない。 - Intel製Arc
ollamaのサポートGPUにIntel製GPUの表記がない。vulkanなら動くかもしれないが自己責任で。ollamaのバージョンによってvulkanで動いたり動かなかったりするので注意。
lemonade
インストール要件
lemonadeのインストールの手段としては、docker用のコンテナ、Fedoraのrpmパッケージ、Ubuntuのdebパッケージが提供されている。しかし、DebianやArchではソースビルドからインストールする必要がある。
注意点
ollamaと比べてインストールにハードルがある反面で、ollamaでは動作しなかったAMD製のGPUでもlemonadeであれば正常に稼働させることができる場合がある。
具体的には、(個人的な調査だが)ollamaではiGPUを認識しなかったRadeon780MでのLLM実行がlemonadeでは正常に動作した。
その他、lemonadeはAPIがOpenAI互換となっており、OllamaのAPIよりもパラメータを詳細に設定できる点は長所でもあり、パラメータが多いと煩雑なので短所でもある。
SearXNG
インストール要件
SearXNGもdockerコンテナが配布されているので、dockerを使う場合はこれを利用する。dockerを使わない場合は、githubのリポジトリを取得してからインストールスクリプト(./utils/searxng.sh)を使用する。
注意点
インストールスクリプトがollamaのように万能ではない。
個人的な感想としては、dockerを使わない場合は「Step by step installation」でインストールした方が良い。「Step by step installation」の内容は少々煩雑なのだが、uWSGIの代わりにnginx-unitを使い、venvの代わりにpyenvを使えばインストールのトラブルを回避しやすいと思う。
インストール後も少し工夫が必要で、settings.ymlに定義されている検索エンジンにはノイズになるAPIが含まれるのでエラー対象のエンジンを除去したり、openwebuiとollama,lemonade,searxngをsystemctlでサービス化して永続化させる工夫が必要になる。
ユースケース
open-webuiにSearXNGを導入することでローカルLLMが「インターネット検索」に対応する
回答が期待できるプロンプト例
- 「Webを検索して最新ニュースからローカルLLM関連の注目記事を選別して要約して下さい」
検索インデックスから抽出する回答から要約したチャットの回答を取得できる。 - 「〇〇市の現在の天気と温度をWebから検索して下さい」
天気予報のような情報も検索インデックスに含まれるので概要は取得できるが「詳細はWebページを開いて下さい」のような回答になる。
回答が期待できないプロンプト例
- 指定のURL https://xxx.mydomain.com/ へアクセスして概要を要約して下さい
直接URLを指定してもLLMからインターネットへの検索はできない。 - Webを検索してAmazonのゲームソフト販売ランキング10位までを抽出して下さい
Amazon内には該当のランキングページがあるが、検索エンジンには公開されていないので情報は取得できない。
API連携の可能性
open-webuiで取得できる情報の限界
- モデルが内蔵している情報 → 取得できる
- open-webuiへ登録した検索エンジン内の情報 → 取得できる
- 登録した検索エンジン以外のインターネットへアクセスする情報 → 取得できない
まとめ
-
open-webui経由のチャットでも、searxngを構築することで検索エンジンと連携した情報が取得できる
-
searxngで取得できる情報は検索エンジンのインデックス情報だけで、リンク先のインターネット上のコンテンツから情報を得ることはできない
-
searxngで取得できる情報には制約があるが、ollama, lemonade,と共に構築する意義は大きい
-
lemonadeを使えば「ollamaでAMD製GPUが使えなかった構成」でもAMD製GPUが正常に認識して動作する場合がある(※Radeon780Mで確認した)
-
ローカルLLMでインターネット上の任意の情報を取得するには、自前のプログラムで任意のURLへアクセスして情報を取得するロジックの構築が不可欠になる。
-
API連携させるためのミドルウェアも多数出ているが、LangChainやn8nのパイプラインを構築するには、「商用APIに耐える課金」もしくは「安定したローカルLLM」が必要になる。自分の環境ではローカルLLMをベースに実用化できるユースケースを検証している。
