目的
- ollama verson 0.30以降から、lamma.cppと同等の推論エンジンになり高速化されたので、その検証
- github copilotが6月1日からの規約変更で使い物にならなくなった。その代替としてローカルLLMを利用する
- Debian / Ubuntu系を前提とした設定
ollamaのアップデート手順
公式のインストールスクリプトを実行すれば最新版が配置されるのだが、serviceファイルが上書きされるのでバックアップしておく
GitHub - ollama/ollama: Get up and running with Kimi-K2.6, GLM-5.2, MiniMax, DeepSeek, gpt-oss, Qwen, Gemma and other models.
Get up and running with Kimi-K2.6, GLM-5.2, MiniMax, DeepSeek, gpt-oss, Qwen, Gemma and other models. - ollama/ollama
github.com
sudo cp /etc/systemd/system/ollama.service ~/$(date "+%Y%m%d")-ollama.service※sudo権限が必要
curl -fsSL https://ollama.com/install.sh | shollamaアップデート後にserviceファイルを確認
sudo vim /etc/systemd/system/ollama.service- CUDAを使う場合はそのまま ollama.service を使えばOK
- アップデート前の設定が必要であればバックアップしたファイルで上書きする
※バックアップしたollama.serviceファイルを使う場合
sudo cp ~/$(date "+%Y%m%d")-ollama.service /etc/systemd/system/ollama.service
sudo systemctl daemon-reload
sudo service ollama restartollama version 0.30から実行ファイルの配置が変わっている
/usr/bin/ollamaを参照している場合は
/usr/local/bin/ollamaへ書き換えておく。
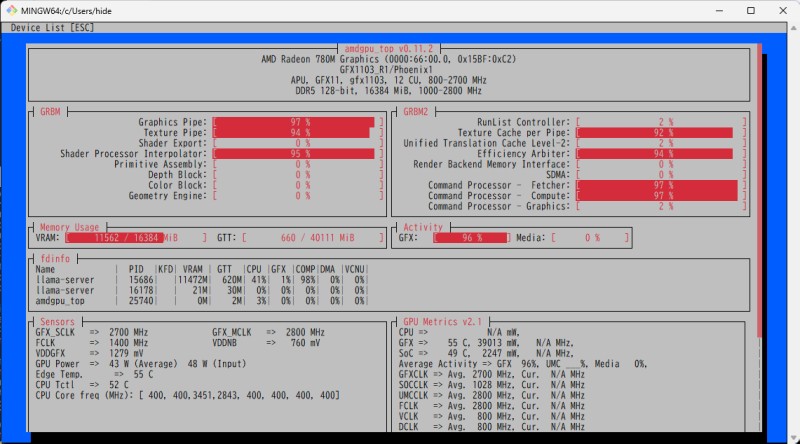
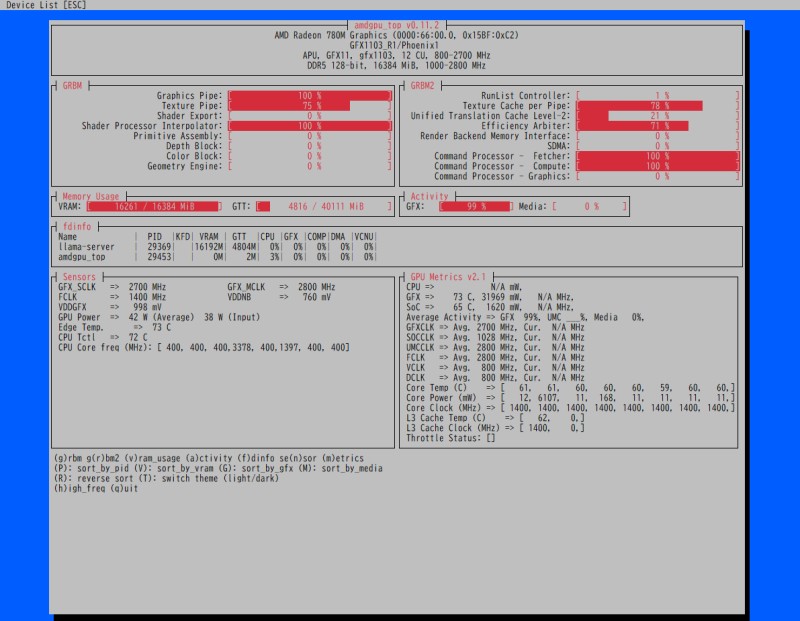
Radeon780Mで利用するための設定
ollama version 0.2x 系でのollama.service
前回の記事を参照
ollamaのバージョン0.20.x以降でRadeon780MのiGPUが認識しなくなった不具合と、lemonadeの導入でRadeon780Mでの推論の稼働が復活した備忘録(※補足:ollama0.22以降だとRadeon780MでのGPU推論が動作した)
不具合の前の状態ollama 16.xではRadeon780Mで動作していたrocmでは動かないvulkanで動作(※環境変数にvulkan用の設定)GPUが認識しない場合は、CPUで動作する不具合のトリガーollama 20.xへのアップ...
blog.hidenori.biz
Environment="HSA_OVERRIDE_GFX_VERSION=11.0.3"
Environment="OLLAMA_VULKAN=1"ollama version 0.30.xx 系でのollama.service
Environment="OLLAMA_IGPU_ENABLE=1"
Environment="OLLAMA_CONTEXT_LENGTH=64000"
Environment="OLLAMA_VULKAN=1"- HSA_OVERRIDE_GFX_VERSION 定義は削除しないとエラー表示になる。
- iGPUを利用する場合はOLLAMA_IGPU_ENABLEの設定が必須。
- OLLAMA_VULKAN=1の定義でVALKANを使用(※iGPUを利用する場合はデフォルトがVULKANなので不要かもしれないが、エラーは出ない)
- OLLAMA_CONTEXT_LENGTHの設定は任意だが、OpenClewやOpenCodeと連携する場合はデフォルト値では動かない
ダウンロード済みのモデルを最新版にアップデート
ollama list | tail -n +2 | awk '{print $1}' | xargs -n1 ollama pull動作確認
ターミナルを2つ起動する
ターミナル1:モニタリング
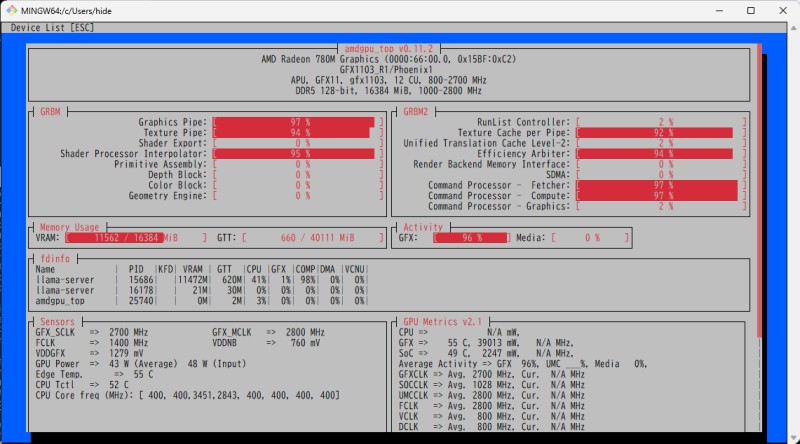
sudo amdgpu_topターミナル2:推論実行
※modelは環境にあわせて変更する
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-oss-20b",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "こんにちは、自己紹介してください"}
],
"temperature": 0.7
}'結果
amdgpu_topのVRAMとGRBM/GRBM2の棒グラフが使用されていればGPUが動作している。

補足
- NVIDIA製GPUでの動作はollamaのデフォルト設定で問題なく動作する
- NVIDIA製GPUの場合はドライバとCUDA設定が必要
- Radeon780MがollamaのサポートGPUリストに入った
https://github.com/ollama/ollama/blob/main/docs/gpu.mdx - 次の記事でOpenCodeの設定について書く予定